Agentic AI for Thermal Comfort and Building Energy in Tropical Urban Neighborhoods
Created in April 18, 2026
2026 · AI for Science · Urban Climate · Agentic Systems
Why This Workflow Matters
In tropical cities like Singapore, the practical questions are not abstract. Which plazas will become pedestrian heat-stress hotspots? Which blocks are driving cooling demand? Which surface strategies improve outdoor comfort without quietly worsening another part of the system?
The hard part is not that we lack simulation tools. It is that neighborhood-scale comfort and energy studies are still awkward to run end to end. Geometry has to be cleaned, weather has to be resolved, multiple solvers have to be configured, and results have to be translated back into something a planner or designer can act on.
The core claim: the most useful role for an LLM here is not to replace the physics, but to coordinate the workflow around the physics.
Let the LLM Coordinate, Not Hallucinate the Physics
The framework in this paper treats the LLM as an orchestrator. A user describes an urban design task in plain language, and the system decides what needs to happen next: interpret the intent, load and index the geometry, resolve weather and material parameters, run the appropriate lightweight solvers, and finally synthesize the outputs into a readable report.
That design choice matters. The LLM handles planning, explanation, and tool routing, while the actual environmental estimates still come from explicit physics-based models for airflow, radiative exchange, thermal comfort, and building heat gain.
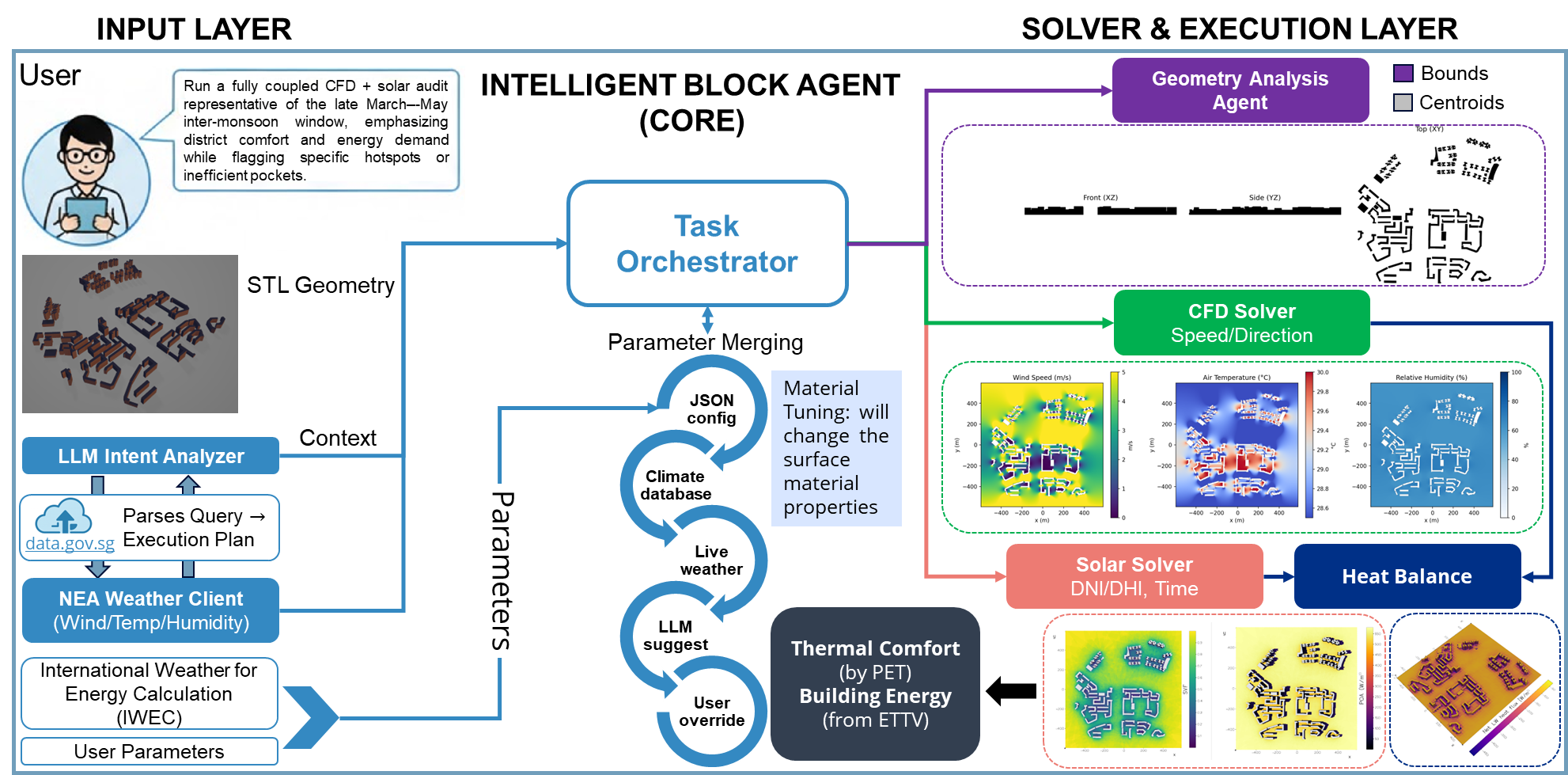
Input Governance Is the Real Product
One of the strongest ideas in the paper is that the LLM is advisory but not authoritative. Solver inputs are filled through a strict priority chain, which makes the workflow auditable instead of conversational in a loose, hand-wavy way.
- Configuration defaults establish structural simulation settings.
- Climate files such as IWEC provide the main hourly weather baseline.
- Optional real-time weather services only fill gaps that remain unset.
- LLM suggestions are applied only when authoritative sources do not provide a value.
- User overrides sit at the highest priority and win over everything else.
That hierarchy is more important than it sounds. It turns the LLM from a source of potentially unstable numerical inputs into a workflow layer whose suggestions are bounded by explicit data governance.
The Physics Stack Stays Lightweight but Explicit
The framework does not aim to reproduce every detail of a full-scale digital twin. Instead, it uses lightweight models that are fast enough for comparative district studies while still remaining physically interpretable.
- A CFD component estimates wind fields using a pseudo-3D strategy built from multiple 2D slices and height interpolation.
- A radiation and surface energy balance model evolves surface temperature from shortwave, longwave, and convective fluxes.
- Thermal comfort is summarized with PET, while cooling demand is approximated from envelope heat transfer into a cumulative energy-use metric.
The point is not to claim that a lightweight model replaces high-fidelity simulation. The point is that an agentic workflow becomes much more usable when the analysis loop is quick enough to support audit, intervention, and comparison in one sitting.
Scenario I: From Semantic Prompt to District-Scale Audit
The baseline test is a good stress test for the orchestration layer because the prompt is intentionally under-specified. The system is asked to run a coupled CFD and solar audit for the late March to May inter-monsoon window, focusing on comfort, energy demand, and hotspot detection, without the user spelling out every numerical parameter.
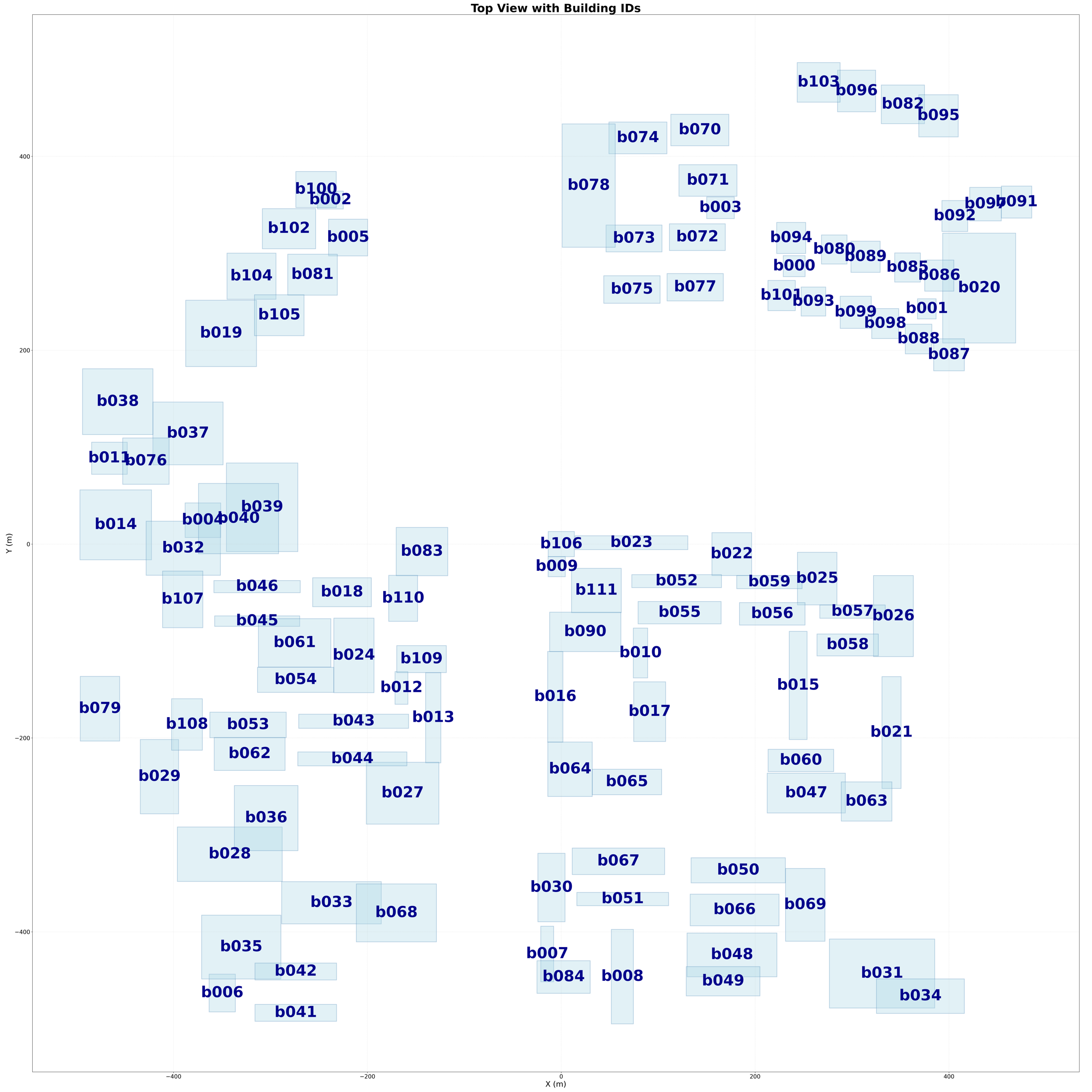
representative district domain used in the study cases
average horizontal resolution around the building clusters
peak PET hotspot detected in District A near buildings b025 and b057
peak PET hotspot detected in District B near buildings b040 and b055
Once the run completes, the system produces spatial PET maps, building-scale cooling indicators, hotspot coordinates, and a readable narrative that ties those results back to geometry and material causes.

Traceability Changes the Conversation
A subtle but important part of the workflow is that geometry is not treated as anonymous mesh data. The pipeline assigns building IDs, extracts footprints and bounding boxes, and generates an index map so that a hotspot in the report can be traced back to a specific part of the district.
That sounds mundane, but it is exactly the difference between “the model says this area is bad” and “building b086 and the plaza near b040 and b055 are the problem.” The latter is a design discussion.
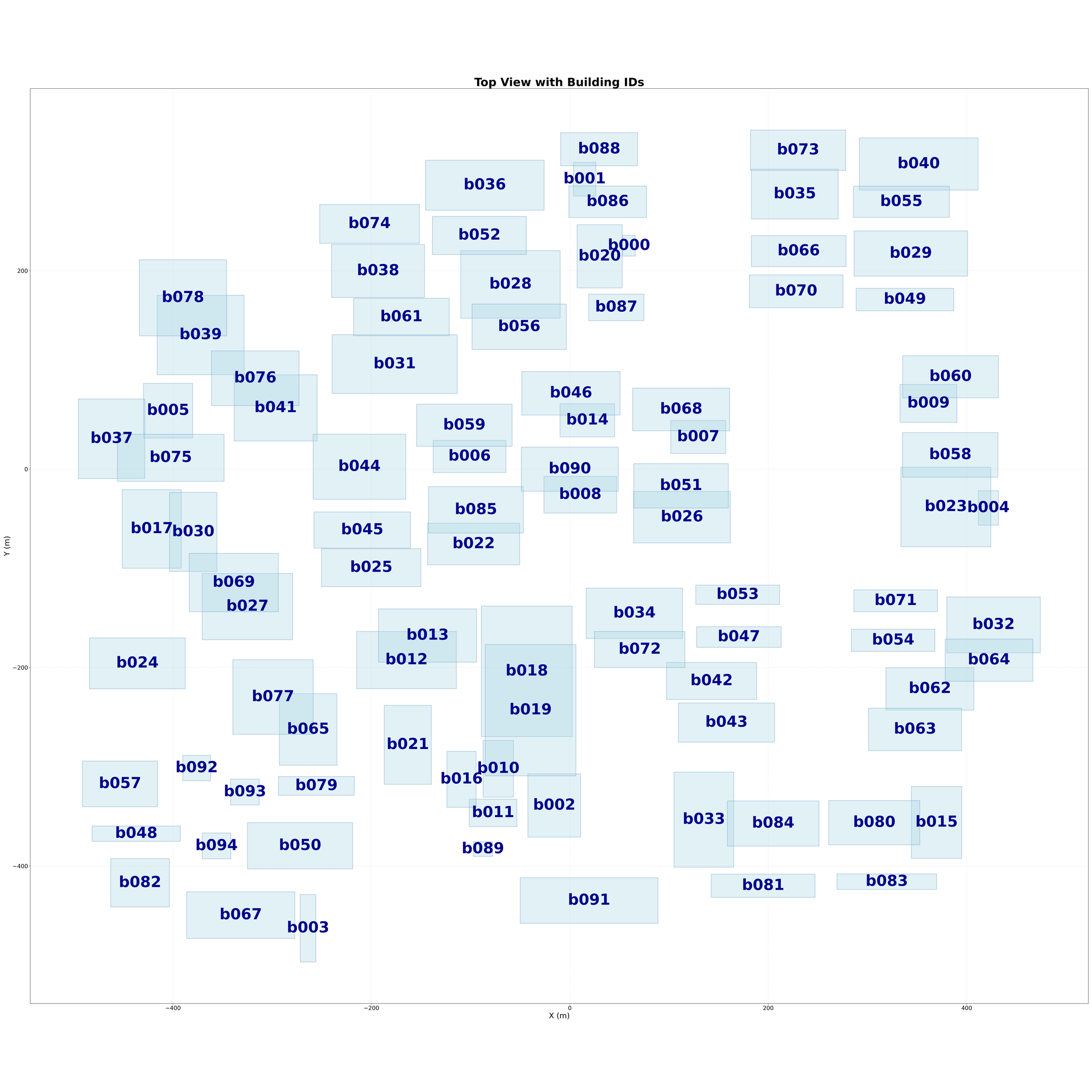
Scenario II: The Closed-Loop Material Intervention
The second scenario is where the framework becomes more than a reporting tool. After the baseline audit, the agent is asked to propose and apply surface material changes that should improve comfort and reduce cooling demand. The system runs a baseline, proposes albedo adjustments, re-simulates, and compares the before-and-after metrics.
This is a useful example of what “agentic” should mean in a scientific setting. The agent is not optimizing by brute force. It is forming a hypothesis, executing it through the physics engine, and then revising its recommendation when the results reveal a trade-off.
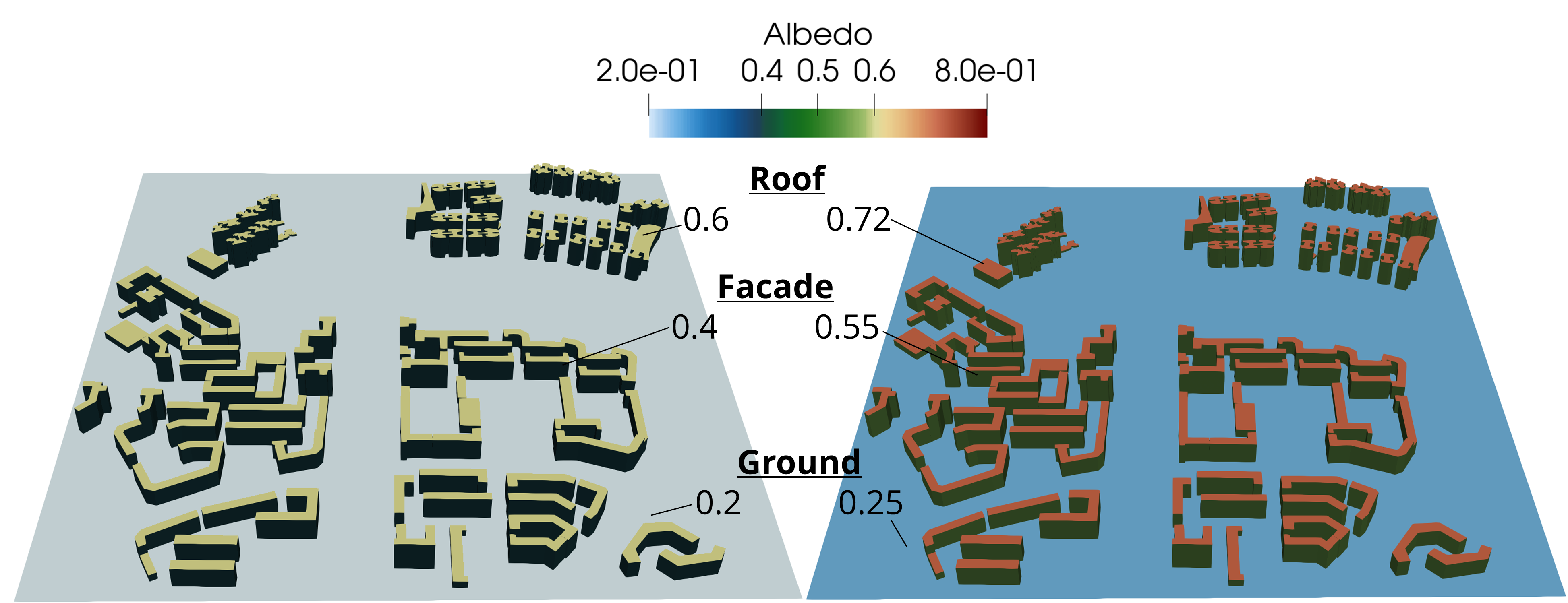
The Most Interesting Result Is the Albedo Penalty
The intervention works for one objective and backfires for another. High-albedo surfaces reduce envelope heat gain and lower cooling demand, but the same bright surfaces can increase shortwave reflection onto pedestrians and slightly worsen thermal comfort at exposed hotspots.
The key lesson: a strategy that looks good from the building envelope can still be bad at pedestrian level. The agent only becomes useful when it can discover that conflict and revise its recommendation.
| Building ID | Description | Cooling-load reduction |
|---|---|---|
| b091 | Tall corner tower | -10.7% |
| b090 | Tall central tower | -10.1% |
| b085 | 46 m tower | -9.6% |
| b077 | 37.7 m block (south) | -11.4% |
| b040 | 32.1 m block (north-east) | -10.8% |
In the reported comparison, representative high-load buildings improve by roughly 8.5% to 11.4% in daily cooling energy, while the noon PET hotspot can increase by about 1°C. That is exactly the kind of cross-objective trade-off that gets lost in single-metric optimization.
What I Think This Means
The most promising part of this work is not that an LLM can write a nicer report. It is that an agent can sit on top of a physics workflow without overriding the domain logic. The agent interprets intent, selects tools, resolves parameters, and explains outcomes, but the actual environmental behavior still comes from explicit models and controlled inputs.
That makes the framework useful in a way many “LLM for simulation” demos are not. It stays conversational where conversation helps, stays deterministic where determinism matters, and makes the resulting analysis traceable enough for cross-disciplinary review.
Citation
This article is adapted from a collaborative conference paper accepted to IAQVEC 2026: Agentic AI-Enabled Framework for Thermal Comfort and Building Energy Assessment in Tropical Urban Neighborhoods .
@inproceedings{lai2026agenticurban,
title={Agentic AI-Enabled Framework for Thermal Comfort and Building Energy Assessment in Tropical Urban Neighborhoods},
author={Lai, Po-Yen and Yang, Xinyu and Low, Derrick and Liu, Huizhe and Wong, Jian Cheng},
year={2026},
booktitle={IAQVEC 2026},
note={Accepted},
url={https://pgupdn.github.io/blog/2026/agentic-urban-comfort-energy/}
}
Enjoy Reading This Article?
Here are a few places to continue: