Drawing Auxiliary Lines: When GNN Input Enrichment Helps Transformers Discover Newton
Created in April 17, 2026
2026 · Inductive Bias · Transformers · Graph Neural Networks
The Central Question
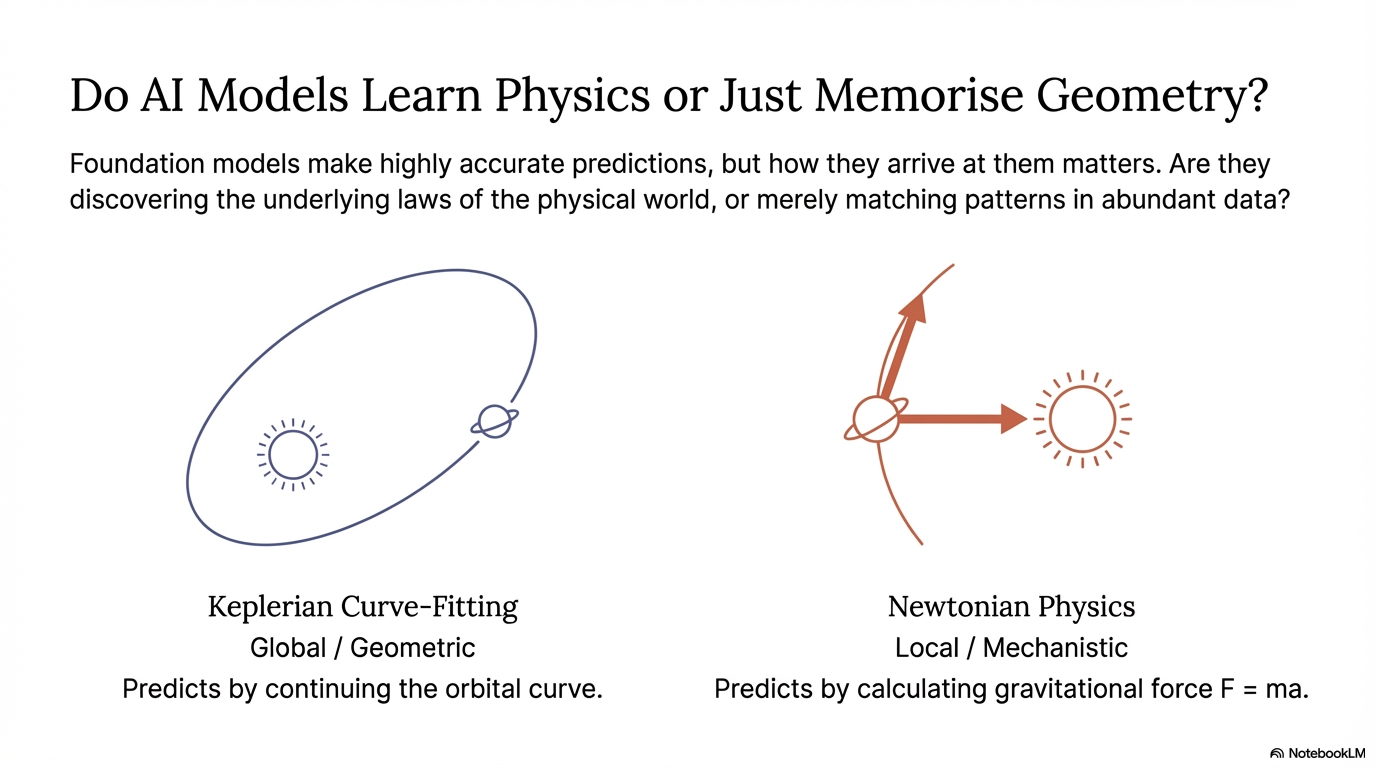
In long-context orbital prediction, Transformers often learn the wrong kind of structure. They become very good at describing the curve and very bad at recovering the law behind it.
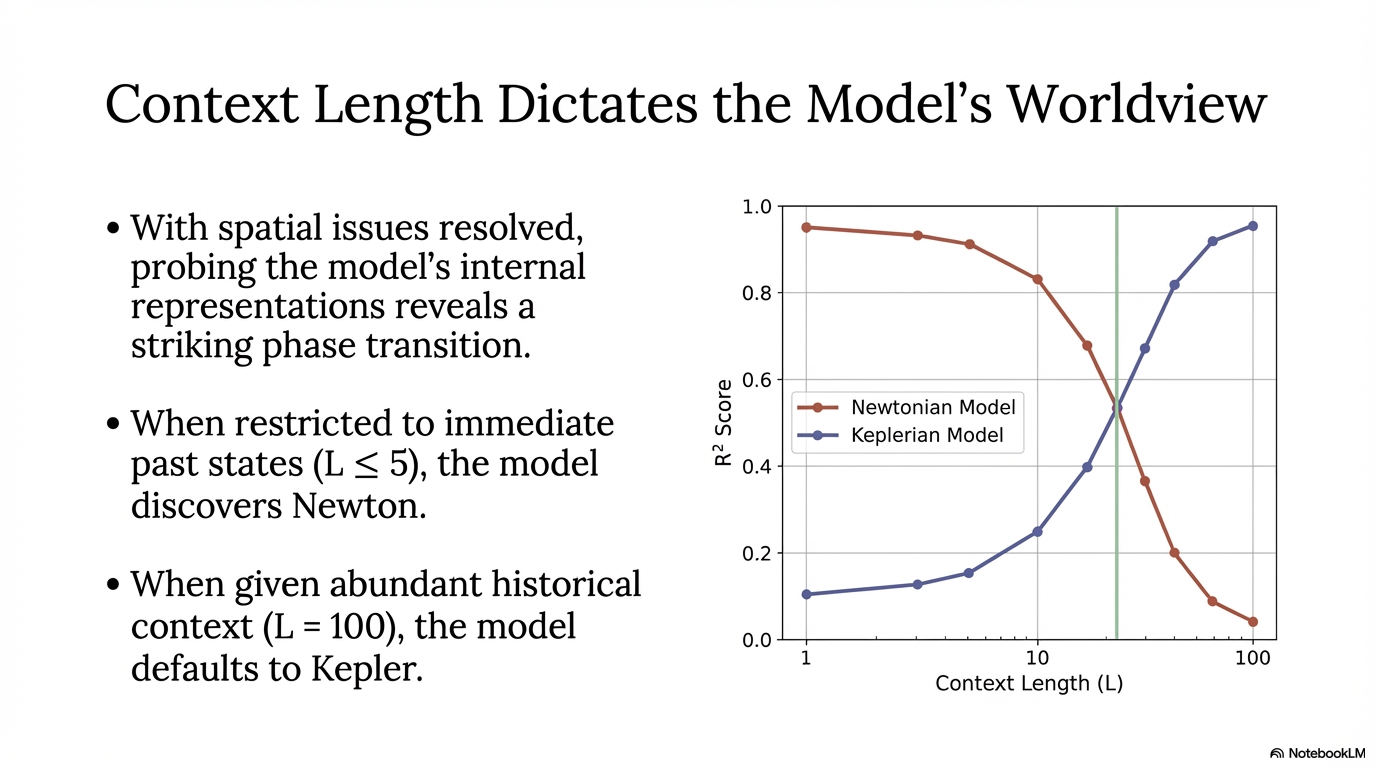
A recent result from Liu et al. made this visible: when the context is short, hidden states line up with Newtonian quantities like force; when the context grows to 100 steps, the same model shifts toward Keplerian geometry. It starts fitting ellipses instead of discovering interaction.[1]
This project asks a narrow question with a broader implication: if a Graph Neural Network already has the right inductive bias for pairwise interaction, what is the best way to inject that bias into a Transformer?
The Metric
I track the difference between Newtonian probe scores and Keplerian probe scores using a single summary value, ΔN, following the probing setup introduced in the original Kepler-to-Newton study.[1]
ΔN = Newtonian representation quality - Keplerian representation quality
Positive values mean the representation is more Newton-like. Negative values mean it leans toward Keplerian structure. The baseline at context length 100 lands at -0.273, which is already a strong hint that the model prefers geometric description over force.
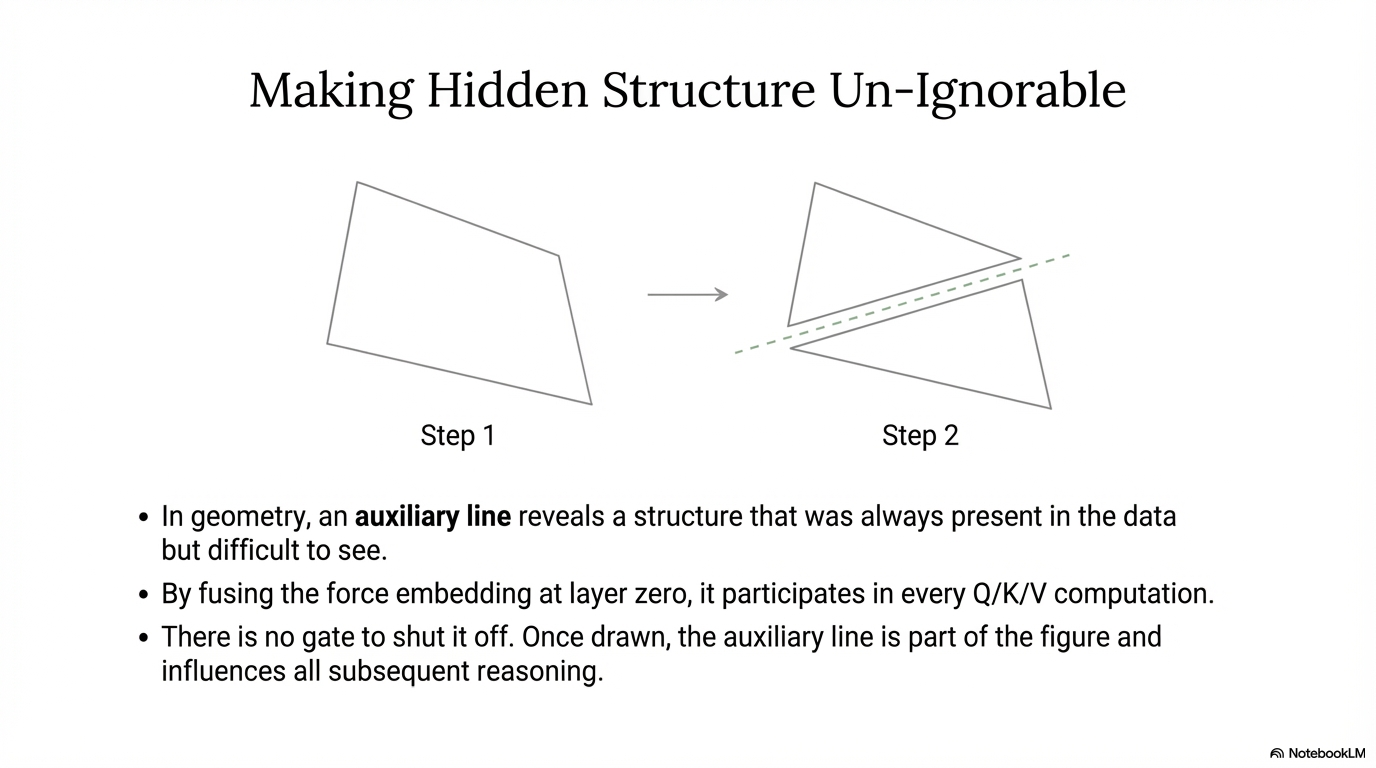
Why "Auxiliary Lines"?
In geometry, an auxiliary line does not add new truth to a figure. It reveals structure that was already there but hard to see. That is the role I wanted the GNN to play here.
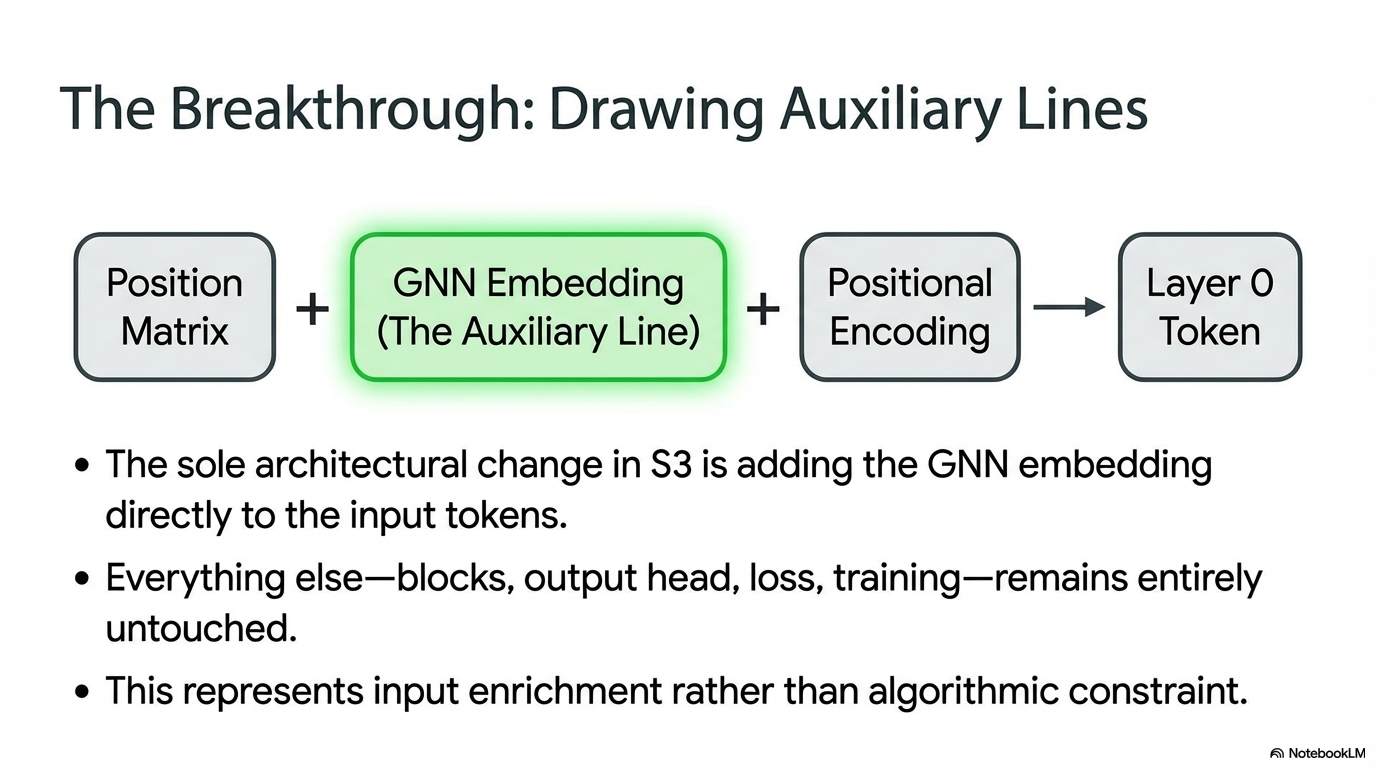
A GNN over the sun and planet nodes naturally computes the kind of relational information Newtonian reasoning needs: who interacts with whom, in what direction, and with what distance-dependent structure. The question is not whether that information exists. The question is how visible it becomes to the Transformer. In the underlying manuscript, I use a Triplet-GMPNN-style relational encoder as the pre-trained graph module.[2]
Three Ways to Inject the GNN
| Strategy | Idea | Outcome |
|---|---|---|
| Cross-attention | The GNN acts as an optional side channel after each block. | The Transformer mostly ignores it. |
| Physics-informed output | The output is routed through a force-flavored bottleneck. | It helps only marginally. |
| Input enrichment | The GNN embedding is added directly to the token embedding. | This produces the strongest shift toward Newton. |
The key distinction is that cross-attention keeps the GNN optional, while input enrichment makes it part of the representation from the first layer onward. The cross-attention branch is inspired by TransNAR-style GNN-Transformer integration, but in this setting that optional route turns out to be exactly the weakness.[3]

Main Result
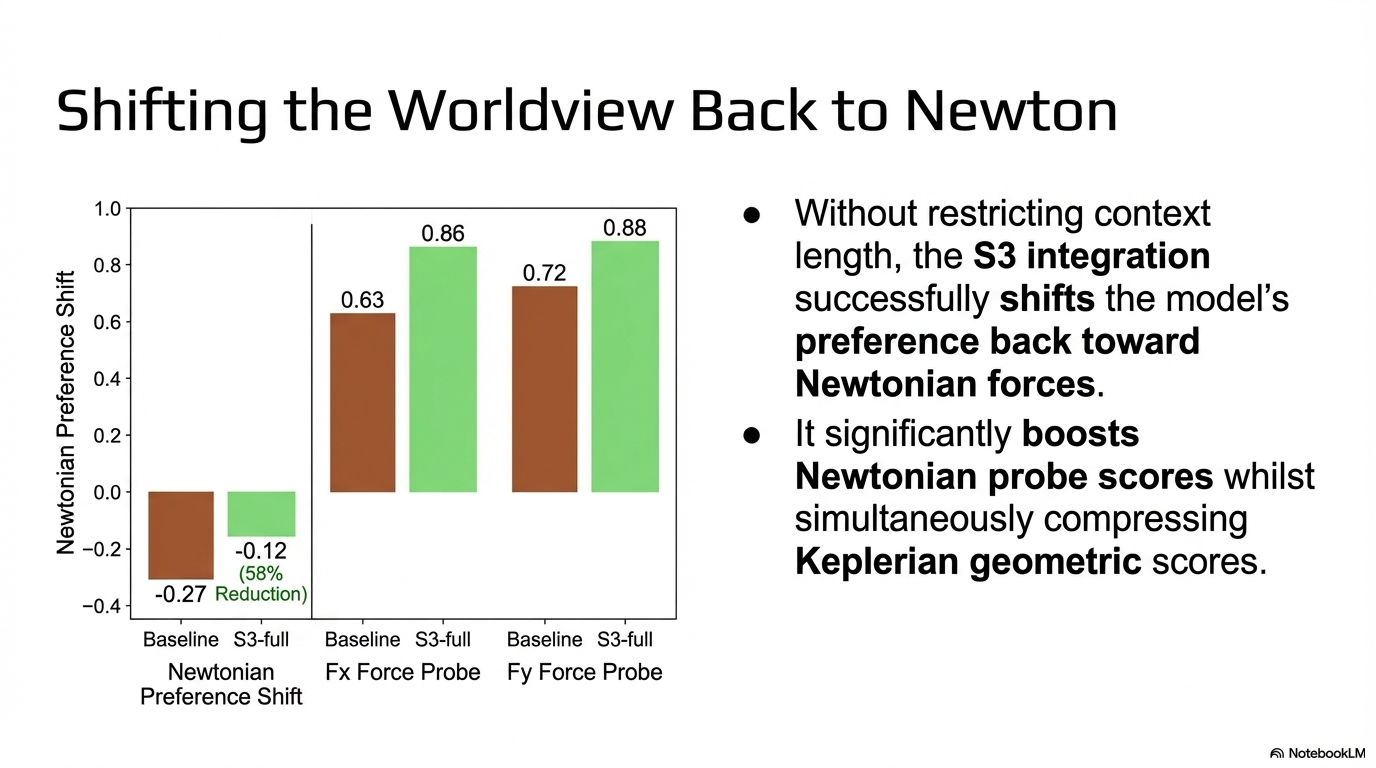
reduction in |ΔN| for the best auxiliary-line variant
Fx probe score after input enrichment
Fy probe score after input enrichment
best final ΔN, improved from -0.273 baseline
Cross-attention variants either failed outright or stayed close to the baseline. Physics-informed outputs improved the metric slightly, but not enough to change the model's underlying preference. Input enrichment was the only strategy that materially changed what the representation cared about.
Why Cross-attention Failed
The baseline Transformer already has a convenient shortcut: fit the orbit geometrically and keep the loss low. Once that shortcut exists, an extra branch has to fight for relevance.
In practice, the GNN remained easy to ignore. A gated route makes this even easier: if the model can minimize loss with Keplerian features, it can simply close the door on the relational signal.
Why Input Enrichment Worked
- The GNN signal enters before the first attention layer, so every Q, K, and V computation starts with relational structure already mixed in.
- The GNN's message passing precomputes the core conceptual step Newton needs: pairwise interaction.
- The richer 128-dimensional relational embedding outperformed the bottleneck variant, which suggests the useful bias is not just a scalar hint but a fuller geometric view.
That is the whole point of the auxiliary-line metaphor: once the line is drawn, the rest of the proof changes.
What I Think This Means
For scientific machine learning, the most effective inductive bias may be representational rather than restrictive. Instead of forcing the model through a bottleneck and hoping it learns the right abstraction, we can sometimes expose the right abstraction earlier and let the model operate on a better figure.
More broadly, this suggests that the question is not only what architecture should I use? but also what structure should the model be allowed to see from the beginning?
References
- Liu, Z., Sanborn, S., Ganguli, S., and Tolias, A. From Kepler to Newton: Inductive Biases Guide Learned World Models in Transformers. arXiv preprint arXiv:2602.06923, 2026.
- Ibarz, B., Kurin, V., Papamakarios, G., Nikiforou, K., Bennani, M., Csordas, R., and Velickovic, P. A Generalist Neural Algorithmic Learner. Learning on Graphs (LoG), 2022.
- Bounsi, W., Ibarz, B., Dudzik, A., Hamrick, J. B., Markeeva, L., Vitvitskyi, A., Pascanu, R., and Velickovic, P. Transformers Meet Neural Algorithmic Reasoners. arXiv preprint arXiv:2406.09308, 2024.
Citation
This article is adapted from my local manuscript Drawing Auxiliary Lines: Graph Neural Networks as Input Enrichment for Newtonian Discovery in Transformers .
@article{yang2026drawingauxiliarylines,
title={Drawing Auxiliary Lines: Graph Neural Networks as Input Enrichment for Newtonian Discovery in Transformers},
author={Yang, Xinyu},
year={2026},
url={https://pgupdn.github.io/blog/2026/drawing-auxiliary-lines/}
}
Enjoy Reading This Article?
Here are a few places to continue: