NeCLO: Turning Maxwell Solvers into Differentiable Tensor Programs
Created in April 17, 2026
2026 · AI for Science · Electromagnetics · Differentiable Solvers
The Friction
Classical FDTD is still one of the most reliable ways to simulate electromagnetic propagation, but the implementation style we inherit from CPU code is a bad fit for modern differentiable workloads. Deeply nested loops do not scale well, and most neural surrogates accelerate by relaxing physical exactness.
This manuscript asks a sharper question: on a regular Yee grid, do we really need a graph at all? Or can we re-express the same Maxwell updates in a form that is more aligned with tensor hardware, while still reproducing the reference solver exactly?
The core claim: on structured grids, differentiable electromagnetics should behave more like a tensor program than a message-passing system.
Why the Graph Baseline Hits a Wall
GEM is a natural baseline because it treats the Yee grid as a directed graph and uses message passing to propagate Maxwell updates. That makes sense if the underlying geometry is irregular. But on a structured grid it introduces avoidable overhead: explicit edges, gather-scatter traffic, and broken memory contiguity.
In other words, the graph abstraction is expressive, but here the geometry is already regular. The abstraction adds machinery where the hardware would rather see dense tensor operations.
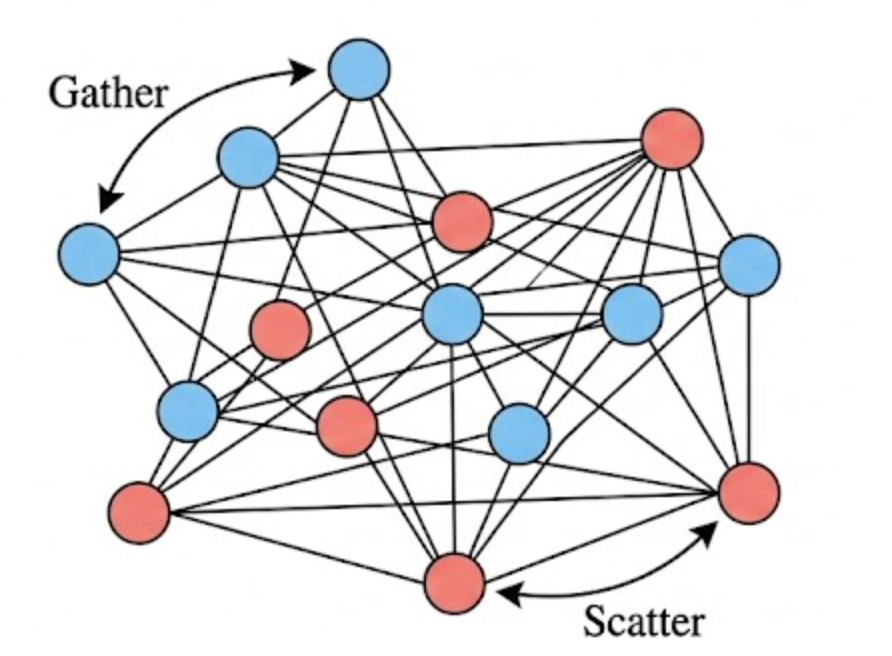
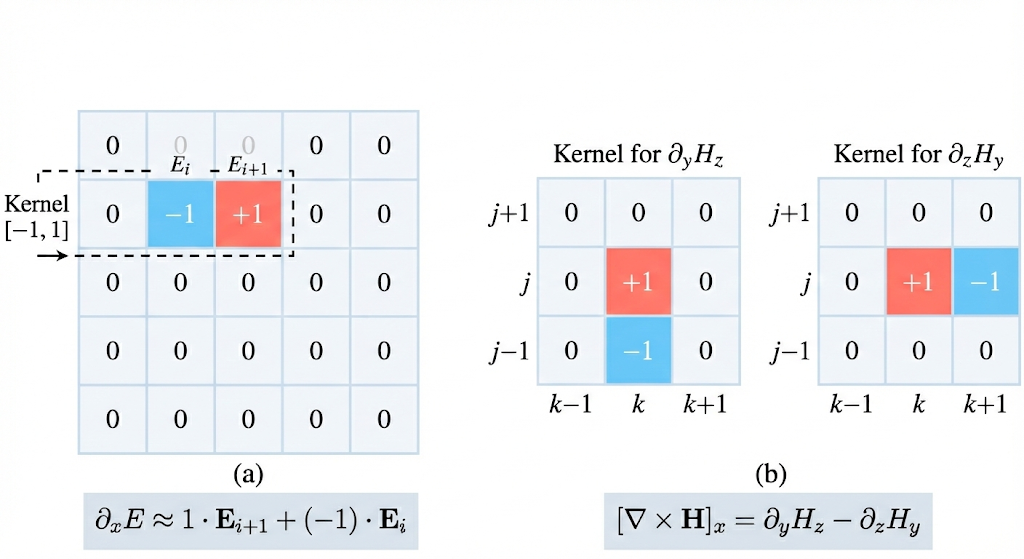
Rewriting Maxwell Updates as Kernels
NeCLO takes the opposite view. Instead of lifting the grid into a
graph, it keeps the domain as a dense voxel tensor and interprets
spatial finite differences as fixed convolution kernels. The curl
operator becomes a small collection of pre-defined
Conv3d filters.
That reframing matters because it is not introducing a neural approximation. It is simply expressing the same local update in a form that optimized tensor libraries and accelerators already know how to execute efficiently.
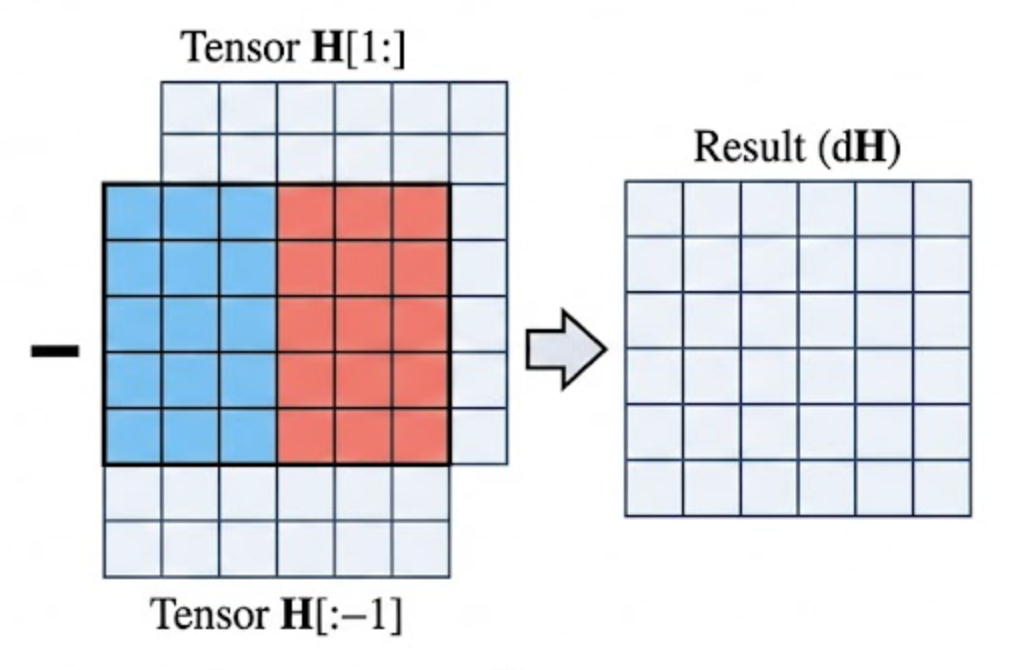
The Stronger Claim: Sometimes Convolution Is Still Too Much
The most interesting part of the work is that it does not stop at
convolution. If a central difference is really just subtraction
between shifted views of the same tensor, then even
Conv3d can be seen as an intermediate abstraction.
That leads to a pure tensor slicing variant: no graph edges, no learnable operator, and no padding-heavy convolution stack. Just direct view shifts and vectorized subtraction. The paper's key insight is that this version is not merely elegant. It is also the fastest.
Main Result
absolute error for NeCLO and tensor slicing in Float32
CPU speedup for NeCLO Conv3d over loop-based FDTD
CPU speedup for pure tensor slicing over loop-based FDTD
final conductivity retrieval error in inversion
| Method | Latency / step | Speedup | Interpretation |
|---|---|---|---|
| Traditional FDTD | 37.0 ms | 1x | Reference implementation with explicit loops |
| NeCLO Conv3d | 0.45 ms | 82x | Exact physics in a dense tensor-kernel form |
| Tensor Slicing | 0.09 ms | 411x | Maximum throughput from raw shifted-view arithmetic |
The accuracy result is just as important as the speed result. GEM remains numerically excellent, but NeCLO and the tensor-slicing variant go further: they reproduce the reference updates bit-for-bit in Float32. That means this is not a surrogate story. It is an implementation story.
Bit-Exactness Changes the Meaning of Acceleration
Most AI-for-science acceleration stories involve a trade: gain speed, lose some amount of physical fidelity, then recover trust by benchmarking carefully. NeCLO is appealing because it sidesteps that trade almost entirely. The update rule is still Maxwell's update rule. Only the computational expression changes.
That is why the visual comparisons matter. The field maps are not merely similar in a qualitative sense. They are a consequence of a tensor implementation that remains mathematically equivalent to the classic stencil.
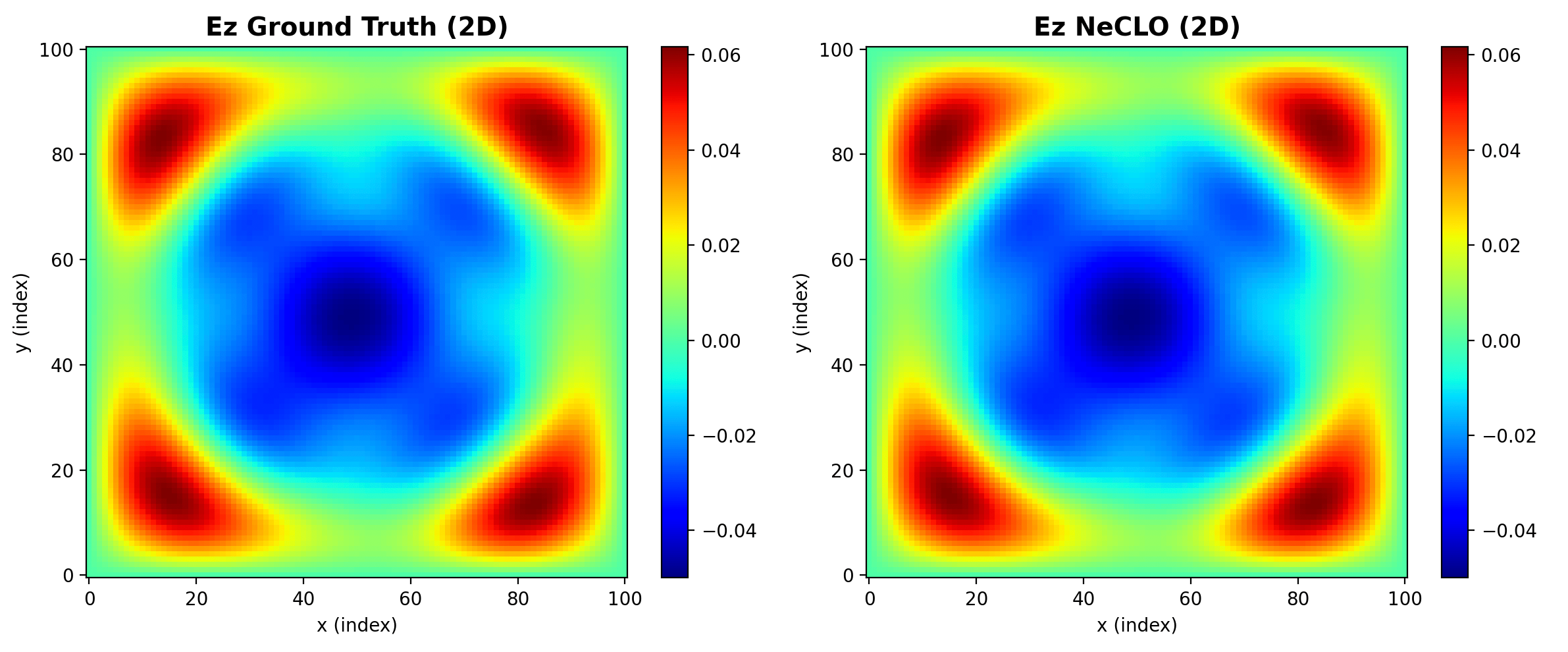
Why NeCLO Still Matters Even If Tensor Slicing Is Faster
The fastest forward implementation is not automatically the best training-time implementation. The manuscript makes a useful distinction here: tensor slicing is extremely fast for forward simulation, but its autograd graph becomes fragmented and memory-bandwidth-bound during learning.
- Tensor slicing minimizes arithmetic overhead, but that same low-level view-shift structure is not ideal for backpropagation.
- NeCLO can still exploit highly optimized tensor kernels, including hardware paths that favor dense convolutional operators.
- That makes NeCLO the better compromise for differentiable inversion, even if pure slicing wins the raw latency contest.
From Solver Acceleration to Inverse Design
The real payoff is not only faster forward simulation. By unrolling the solver and keeping the whole pipeline differentiable, the work turns conductivity retrieval into a direct optimization problem. In the reported experiment, the learned conductivity converges back to the ground-truth 4.0 S/m within 500 epochs, with error on the order of 10-5.
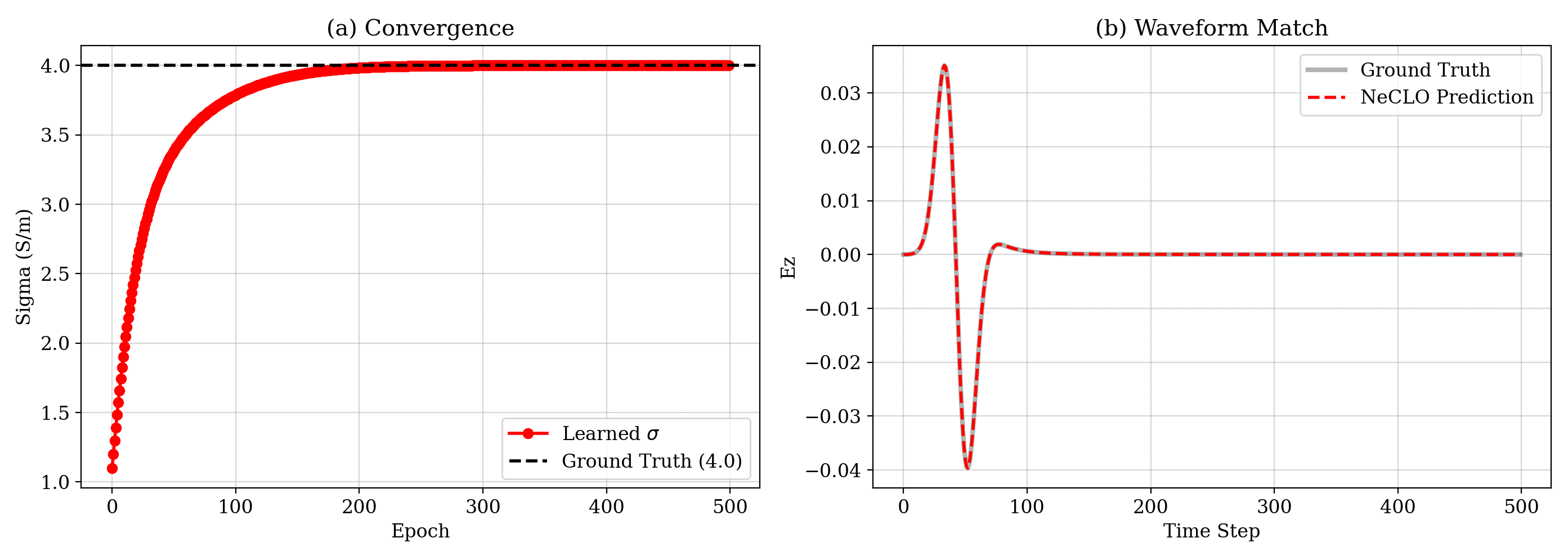
What I Think This Means
For AI for science, this is a reminder that not every acceleration problem should be handed first to a learned surrogate. Sometimes the deeper win is representational: choose the computational form that matches the structure of the physics and the structure of the hardware at the same time.
NeCLO is compelling because it sits exactly in that overlap. It keeps Maxwell's equations intact, stays differentiable enough for inverse design, and rewrites a classical solver into something modern accelerators can execute naturally. That feels less like replacing physics with AI, and more like compiling physics into the right substrate.
Citation
This article is adapted from a collaborative manuscript: NeCLO: Neural Convolutional Learning Optimizer for Electromagnetics .
@misc{zhang2026neclo,
title={NeCLO: Neural Convolutional Learning Optimizer for Electromagnetics},
author={Zhang, Yanxin and Yang, Zaifeng and Yang, Xinyu and Lyu, Yueming},
year={2026},
note={AI4X -- Accelerate 2026 manuscript},
url={https://pgupdn.github.io/blog/2026/neclo-differentiable-electromagnetics/}
}
Enjoy Reading This Article?
Here are a few places to continue: